
How AlphaZero Learns Chess
AlphaZero's learning process is, to some extent, similar to that of humans. A new paper from DeepMind, which includes a contribution from the 14th world chess champion Vladimir Kramnik, provides strong evidence for the existence of human-understandable concepts in AlphaZero's network, even though AlphaZero has never seen a human game of chess.
How does AlphaZero learn chess? Why does it make certain moves? What values does it give to concepts such as king safety or mobility? How does it learn openings, and how is that different from how humans developed opening theory?
Questions like these are being discussed in a fascinating new paper by DeepMind, titled Acquisition of Chess Knowledge in AlphaZero. It was written by Thomas McGrath, Andrei Kapishnikov, Nenad Tomasev, Adam Pearce, Demis Hassabis, Been Kim, and Ulrich Paquet together with Kramnik. It is the second cooperation between DeepMind and Kramnik, after their research from last year when they used AlphaZero to explore the design of different variants of the game of chess, with different sets of rules.
Encoding Human Conceptual Knowledge
In their latest paper, the researchers tried a method for encoding human conceptual knowledge, to determine the extent to which the AlphaZero network represents human chess concepts. Examples of such concepts are the bishop pair, material (im)balance, mobility, or king safety. These concepts have in common that they are pre-specified functions that encapsulate a particular piece of domain-specific knowledge.
Some of these concepts were taken from Stockfish 8's evaluation function, such as material, imbalance, mobility, king safety, threats, passed pawns, and space. Stockfish 8 uses these as sub-functions that give individual scores leading to a "total" evaluation that is exported as a continuous value, such as "0.25" (a slight advantage to White) or "-1.48" (a big advantage to Black). Note that more recent versions of Stockfish have developed into Alpha-Zero-like neural networks but were not used for this paper.
The third type of concepts encapsulates more specific lower-level features, such as the existence of forks, pins, or contested files, as well as a range of features regarding pawn structure.
Having established this wide array of human concepts, the next step for the researchers was to try and find them within the AlphaZero network, for which they used a sparse linear regression model. After that, they started visualizing the human concept learning with what they call what-when-where plots: what concept is learned when in training time where in the network.
According to the researchers, AlphaZero indeed develops representations that are closely related to a number of human concepts over the course of training, including high-level evaluation of the position, potential moves and consequences, and specific positional features.
One interesting result was about material imbalance. As was demonstrated in Matthew Sadler and Natasha Regan's award-winning book Game Changer: AlphaZero’s Groundbreaking Chess Strategies and the Promise of AI (New In Chess, 2019), AlphaZero seems to view material imbalance differently from Stockfish 8. The paper gives empirical evidence that this is the case at the representational level: AlphaZero initially "follows" Stockfish 8's evaluation of material more and more during its training, but at some point, it turns away from it again.
Piece Value & Material
The next step for the researchers was to relate the human concepts to AlphaZero's value function. One of the first concepts they looked at was piece value, something a beginner will first learn when starting to play chess. The classical values are nine for a queen, five for a rook, three for both the bishop and knight, and one for a pawn. The left figure below (taken from the paper) shows the evolution of piece weights during AlphaZero's training, with piece values converging towards commonly-accepted values.
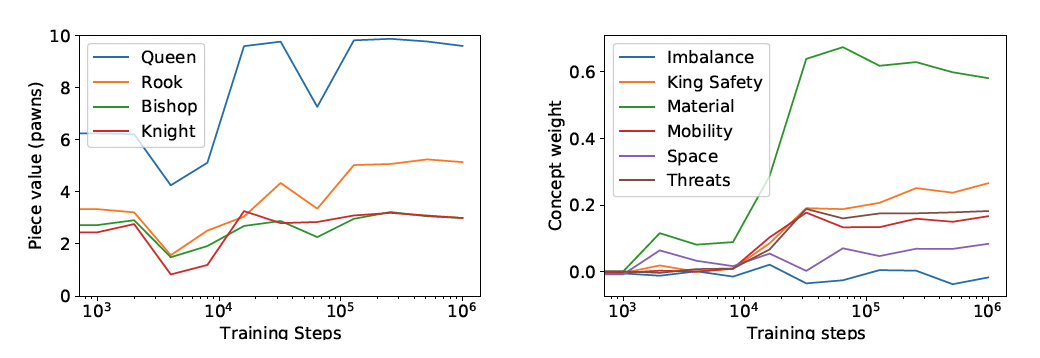
The image on the right shows that during AlphaZero's training, material becomes more and more important in the early stages of learning chess (consistent to human learning) but it reaches a plateau and at some point, the values of more subtle concepts such as mobility and king safety are becoming more important while material actually decreases in importance.
AlphaZero Training Vs. Human Knowledge Over History
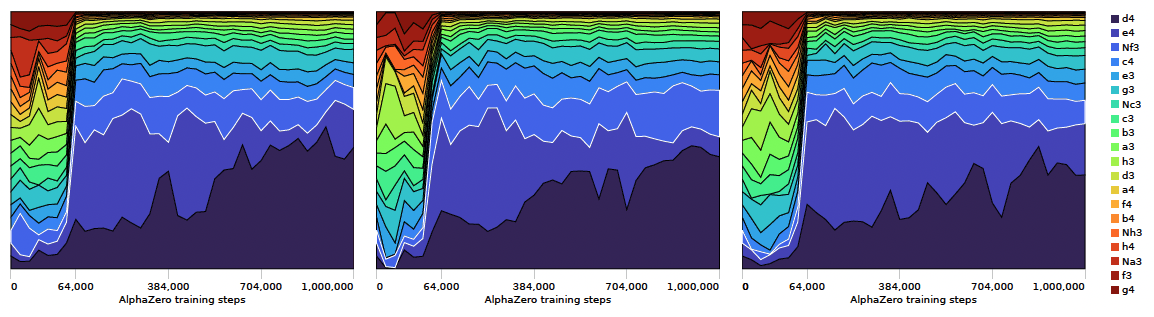
Another part of the paper is dedicated to comparing AlphaZero's training to the progression of human knowledge over history. The researchers point out that there is a marked difference between AlphaZero’s progression of move preferences through its history of training steps, and what is known of the progression of human understanding of chess since the 15th century:
AlphaZero starts with a uniform opening book, allowing it to explore all options equally, and largely narrows down plausible options over time. Recorded human games over the last five centuries point to an opposite pattern: an initial overwhelming preference for 1.e4, with an expansion of plausible options over time.
The researchers compare the games AlphaZero is playing against itself with a large sample taken from the ChessBase Mega Database, starting with games from the year 1475 up till the 21st century.
Humans initially played 1.e4 almost exclusively but 1.d4 was slightly more popular in the early 20th century, soon followed by the increasing popularity of more flexible systems like 1.c4 and 1.Nf3. AlphaZero, on the other hand, tries out a wide array of opening moves in the early stage of its training before starting to value the "main" moves higher.
The Berlin Ruy Lopez
A more specific example provided is about the Berlin variation of the Ruy Lopez (the move 3...Nf6 after 1.e4 e5 2.Nf3 Nc6 3.Bb5), which only became popular at the top level early 21st century, after Kramnik successfully used it in his world championship match with GM Garry Kasparov in 2000. Before that, it was considered to be somewhat passive and slightly better for White with the move 3...a6 being preferable.
The researchers write:
Looking back in time, it took a while for human chess opening theory to fully appreciate the benefits of Berlin defense and to establish effective ways of playing with Black in this position. On the other hand, AlphaZero develops a preference for this line of play quite rapidly, upon mastering the basic concepts of the game. This already highlights a notable difference in opening play evolution between humans and the machine.
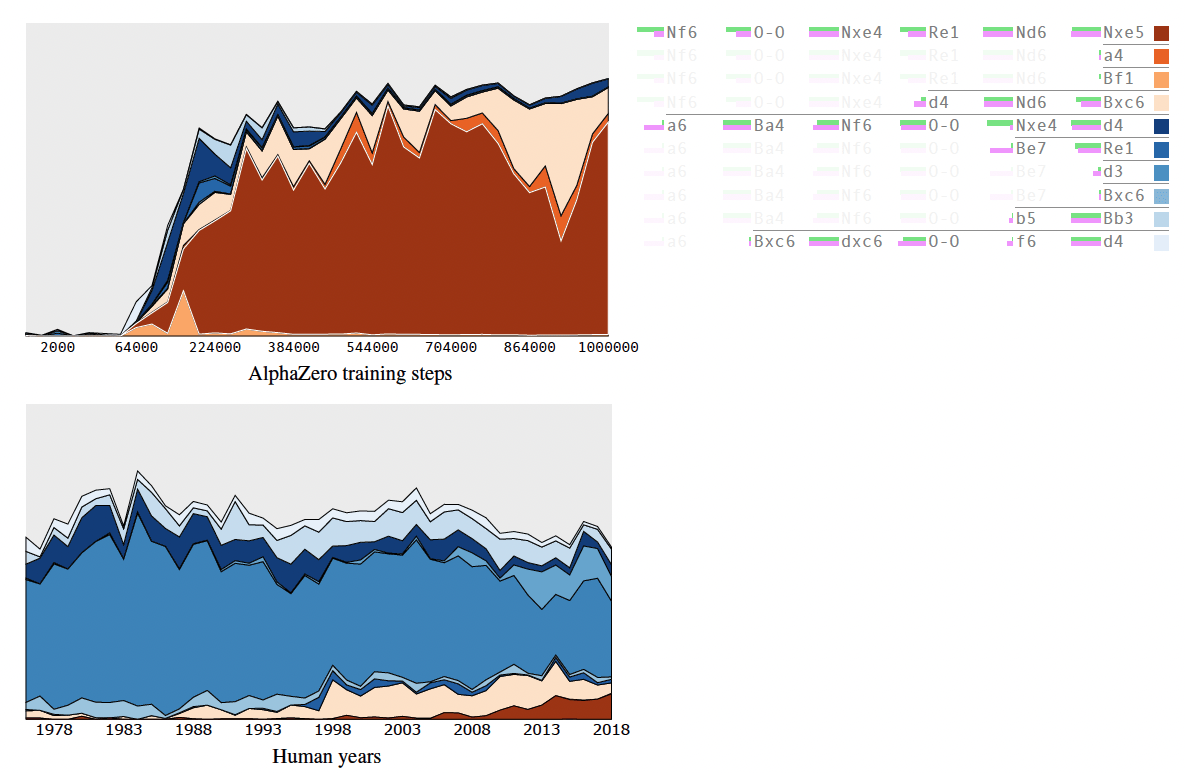
Remarkably, when different versions of AlphaZero are trained from scratch, half of them strongly prefer 3… a6, while the other half strongly prefer 3… Nf6! It is interesting as it means that there is no "unique” good chess player. The following table shows the preferences of four different AlphaZero neural networks:
| AZ version 1 | AZ version 2 | AZ version 3 | AZ version 4 | |
| 3… Nf6 | 5.50% | 92.80% | 88.90% | 7.70% |
| 3… a6 | 89.20% | 2.00% | 4.60% | 85.80% |
| 3… Bc5 | 0.70% | 0.80% | 1.30% | 1.30% |
The AlphaZero prior network preferences after 1. e4 e5 2. Nf3 Nc6 3. Bb5, for four different training runs of the system (four different versions of AlphaZero). The prior is given after one million training steps. Sometimes AlphaZero converges to become a player that prefers 3… a6, and sometimes AlphaZero converges to become a player that prefers to respond with 3… Nf6.
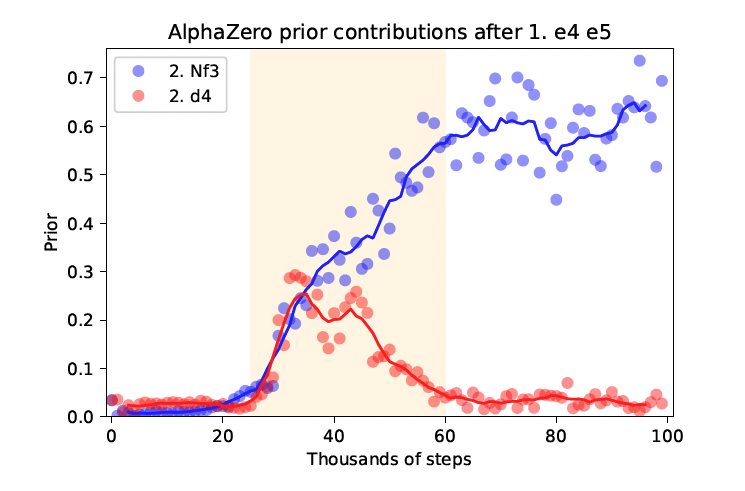
In a similar vein, AlphaZero develops its own opening "theory" for a much wider array of openings over the course of its training. At some point, 1.d4 and 1.e4 are discovered to be good opening moves and are rapidly adopted. Similarly, AlphaZero's preferred continuation after 1.e4 e5 is determined in another short temporal window. The figure below illustrates how both 2.d4 and 2.Nf3 are quickly learned as reasonable White moves, but 2.d4 is then dropped almost as quickly in favor of 2.Nf3 as a standard reply.
Kramnik's Qualitative Assessment
Kramnik's contribution to the paper is a qualitative assessment, as an attempt to identify themes and differences in the style of play of AlphaZero at different stages of its training. The 14th world champion was provided sample games from four different stages to look at.
According to Kramnik, in the early training stage, AlphaZero has "a crude understanding of material value and fails to accurately assess material in complex positions. This leads to potentially undesirable exchange sequences, and ultimately losing games on material." In the second stage, AlphaZero seemed to have "a solid grasp on material value, thereby being able to capitalize on the material assessment weakness" of the early version.
In the third stage, Kramnik feels that AlphaZero has a better understanding of king safety in imbalanced positions. This manifests in the second version "potentially underestimating the attacks and long-term material sacrifices of the third version, as well as the second version overestimating its own attacks, resulting in losing positions."
In its fourth stage of the training, has a "much deeper understanding" of which attacks will succeed and which would fail. Kramnik notices that it sometimes accepts sacrifices played by the "third version," proceeds to defend well, keep the material advantage, and ultimately converts to a win.
Another point Kramnik makes, which feels similar to how humans learn chess, is that tactical skills appear to precede positional skills as AlphaZero learns. By generating self-play games over separate opening sets (e.g. the Berlin or the Queen's Gambit Declined in the "positional" set and the Najdorf and King's Indian in the "tactical" set), the researchers manage to provide circumstantial evidence but note that further work is needed to understand the order in which skills are acquired.

Implications Outside Chess
For a long time, it was believed that machine-learning systems learn uninterpretable representations that have little in common with human understanding of the domain they are trained on. In other words, how and what AI teaches itself is mostly gibberish to humans.
With their latest paper, the researchers have provided strong evidence for the existence of human-understandable concepts in an AI system that wasn't exposed to human-generated data. AlphaZero's network shows the use of human concepts, even though AlphaZero has never seen a human game of chess.
This might have implications outside the chess world. The researchers conclude:
The fact that human concepts can be located even in a superhuman system trained by self-play broadens the range of systems in which we should expect to find human-understandable concepts. We believe that the ability to find human-understandable concepts in the AZ network indicates that a closer examination will reveal more.
Co-author Nenad Tomasev commented to Chess.com that for him personally, he was really curious to consider if there is such a thing as a "natural" progression of chess theory:
Even in the human context—if we were to 'restart' history, go back in time—would the theory of chess have developed in the same way? There were a number of prominent schools of thought in terms of the overall understanding of chess principles and middlegame positions: the importance of dynamism vs. structure, material vs. sacrificial attacks, material imbalance, the importance of space vs. the hypermodern school that invites overextension in order to counterattack, etc. This also informed the openings that were played. Looking at this progression, what remains unclear is whether it would have happened the same way again. Maybe some pieces of chess knowledge and some perspectives are simply easier and more natural for the human mind to grasp and formulate? Maybe the process of refining them and expanding them has a linear trajectory, or not? We can't really restart history, so we can only ever guess what the answer might be.
However, when it comes to AlphaZero, we can retrain it many times—and also compare the findings to what we have previously seen in human play. We can therefore use AlphaZero as a Petri dish for this question, as we look at how it acquires knowledge about the game. As it turns out, there are both similarities and dissimilarities in how it builds its understanding of the game compared to human history. Also, while there is some level of stability (results being in agreement across different training runs), it is by no means absolute (sometimes the training progression looks a little bit different, and different opening lines end up being preferred).
Now, this is by no means a definitive answer to what is, to me personally, a fascinating question. There is still plenty to think about here. Yet, we hope that our results provide an interesting perspective and make it possible for us to start thinking a bit deeper about how we learn, grow, improve—the very nature of intelligence and how it goes all the way from a blank slate to what is a deep understanding of a very complex domain like chess.
Kramnik commented to Chess.com:
"There are two major things which we can try to find out with this work. One is: how does AlphaZero learn chess, how does it improve? That is actually quite important. If we manage one day to understand it fully, then maybe we can interpret it into the human learning process.
Secondly, I believe it is quite fascinating to discover that there are certain patterns that AlphaZero finds meaningful, which actually make little sense for humans. That is my impression. That actually is a subject for further research, in fact, I was thinking that it might easily be that we are missing some very important patterns in chess, because after all, AlphaZero is so strong that if it uses those patterns, I suspect they make sense. That is actually also a very interesting and fascinating subject to understand, if maybe our way of learning chess, of improving in chess, is actually quite limited. We can expand it a bit with the help of AlphaZero, of understanding how it sees chess."

Peter Doggers joined a chess club a month before turning 15 and still plays for it. He used to be an active tournament player and holds two IM norms. Peter has a Master of Arts degree in Dutch Language & Literature. He briefly worked at New in Chess, then as a Dutch teacher and then in a project for improving safety and security in Amsterdam schools. Between 2007 and 2013 Peter was running ChessVibes, a major source for chess news and videos acquired by Chess.com in October 2013. As our Director News & Events, Peter writes many of our news reports. In the summer of 2022, The Guardian’s Leonard Barden described him as “widely regarded as the world’s best chess journalist.”
Peter's first book The Chess Revolution is out now!
Company Contact and News Accreditation:
Email: [email protected] FOR SUPPORT PLEASE USE chess.com/support!
Phone: 1 (800) 318-2827
Address: 877 E 1200 S #970397, Orem, UT 84097

